Advertisement
Stable Diffusion has quickly become one of the most recognizable names in AI-generated imagery. Known for turning text into high-quality visuals, it's commonly associated with PyTorch. However, there's now increasing interest in running it with JAX and Flax. This isn't just about trying something new—it’s about tapping into JAX’s speed, scalability, and cleaner design for research and deployment.
Using JAX brings performance benefits and a more functional approach to model training and inference. In this article, we look at why Stable Diffusion in JAX matters, what it takes to get it running, and how it compares with the usual setups.
JAX is a high-performance numerical computing library from Google that shines in machine learning research. It comes with automatic differentiation, XLA compilation, and built-in support for GPUs and TPUs. Flax builds on this by offering a minimal, flexible neural network library tailored for JAX.
Diffusion models, such as Stable Diffusion, require repeated operations—adding noise and then gradually reversing it to form an image. JAX handles this well through parallelism and function compilation. Its pmap and vmap tools allow easy parallel execution across devices. These capabilities are especially useful for large-scale training or batch image generation.
The functional style in JAX keeps model logic cleaner. Unlike PyTorch, which often uses class-based models with hidden states, JAX treats models as pure functions. All model parameters and states are passed explicitly, making the code more predictable and reproducible. This becomes a real strength when scaling experiments or comparing results.
Training large diffusion models often involves attention mechanisms, U-Net backbones, and embedding from language models. These elements require precise control over tensors and randomness—something JAX supports well through its explicit handling of random number generation using RNG keys.
Porting Stable Diffusion from PyTorch to JAX is a non-trivial process. You can't just convert lines one-to-one—every aspect of model design and training must align with JAX's functional approach. Instead of relying on state_dicts and class objects, JAX organizes model parameters as nested dictionaries passed to and from functions.
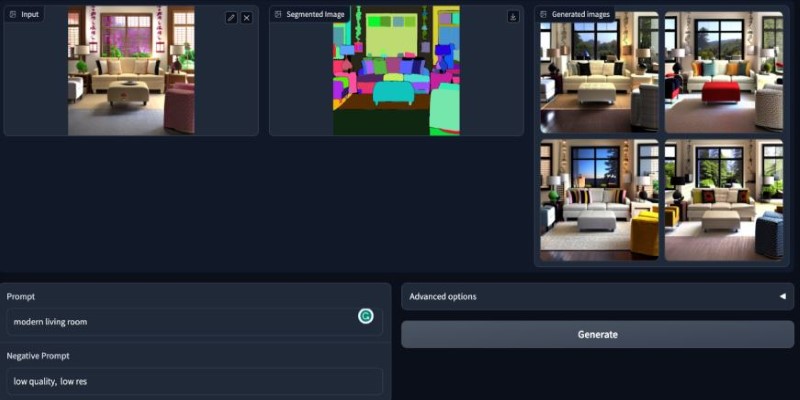
The core model—the U-Net used for denoising—maps well to Flax, but attention layers and residual connections must be carefully rebuilt to match the original behaviour. Small differences in numerical operations or layer initialization can lead to noticeably different image outputs.
Another layer of complexity is the text encoder. Stable Diffusion utilises a pre-trained language model, such as CLIP, for conditioning. In a JAX setup, this requires re-implementing or reusing compatible Flax models, often pulled from Hugging Face's model hub. These encoders need to remain consistent with the PyTorch versions for quality to hold up.
The noise scheduling process—how noise is added and reversed—must also match exactly. The schedule, timesteps, and beta parameters have to be implemented without drift. Even a small error in the denoising process will reduce output quality or introduce artifacts.
Despite these challenges, community efforts, such as Hugging Face's diffusers library and independent projects, have made significant progress. Pretrained weights are now available, and some JAX implementations can generate images with fidelity close to their PyTorch counterparts.
JAX’s main strength is performance, especially when using TPUs or running large-scale experiments. While compilation takes time, once complete, the speed of compiled functions can be significantly higher than dynamic execution in PyTorch. This helps in both training and inference scenarios.
Another benefit is the clarity of the code. In JAX, randomness, model parameters, and intermediate states are explicitly handled, reducing hidden side effects. This makes the training process more transparent and reproducible, especially in collaborative or long-running projects.
Scalability is another big reason developers are looking at JAX. With functions like pjit and xmap, you can run operations across multiple devices or slices of large models. This makes it easier to work with higher-resolution images or longer-generation chains without running into memory or speed bottlenecks.
Memory efficiency is another strength. Because JAX compiles static graphs and doesn’t carry the dynamic overhead of PyTorch, it can often run models with lower memory usage. That makes it possible to run larger batch sizes or work with more detailed images during both training and inference.
Inference in JAX is generally fast once compiled, though startup time can be longer. For repeated runs or serving through an API, the speed gains often make up for the delay. TPU support gives JAX another edge, especially for teams working in Google Cloud or with academic access to TPU resources.
While PyTorch dominates the open-source AI space, JAX is steadily growing, especially in research. More papers and labs are adopting it for large experiments, and community libraries are improving. Tools like Hugging Face’s Transformers and Flax are helping bridge the gap between PyTorch and JAX ecosystems.

Still, most tutorials, pre-trained models, and community discussions begin in PyTorch. This means JAX users often need to do extra work to port models or adapt pipelines. But the process is getting easier as more Flax-based checkpoints and scripts become available.
JAX encourages a different style of experimentation. Its functional approach reduces side effects, which can lead to cleaner models and better debugging. For those building Stable Diffusion from scratch or fine-tuning, this level of control can help avoid subtle bugs and improve outcomes.
Hybrid setups are also becoming more common, where components like text encoding run in PyTorch, and others, such as the denoising U-Net, run in JAX. This lets developers mix tools based on performance and flexibility needs.
JAX isn't for everyone, but for cases involving custom training, TPUs, or large-scale work, it’s becoming a strong alternative. Stable Diffusion is just one example where it can have a noticeable impact.
Stable Diffusion in JAX and Flax offers a cleaner, faster, and more scalable alternative to traditional PyTorch setups. While the ecosystem is still growing, it’s already a solid option for researchers and developers working on performance-sensitive or TPU-based projects. With increasing community support and improved tooling, JAX is proving that it’s more than capable of handling advanced image generation tasks in a functional and efficient way.
Advertisement
Explore how Neo4j uses graph structures to efficiently model relationships in social networks, fraud detection, recommendation systems, and IT operations—plus a practical setup guide

Discover lesser-known Pandas functions that can improve your data manipulation skills in 2025, from query() for cleaner filtering to explode() for flattening lists in columns

How fine-tuning CLIP with satellite data improves its performance in interpreting remote sensing images and captions for tasks like land use mapping and disaster monitoring

How a course launch community event can boost engagement, create meaningful interaction, and shape a stronger learning experience before the course even starts

Looking for practical data science tools? Explore ten standout GitHub repositories—from algorithms and frameworks to real-world projects—that help you build, learn, and grow faster in ML

New to YARN? Learn how YARN manages resources in Hadoop clusters, improves performance, and keeps big data jobs running smoothly—even on a local setup. Ideal for beginners and data engineers

How does HDFS handle terabytes of data without breaking a sweat? Learn how this powerful distributed file system stores, retrieves, and safeguards your data across multiple machines

Learn the full process of deploying ViT on Vertex AI for scalable and efficient image classification. Discover how to prepare, containerize, and serve Vision Transformer models in production
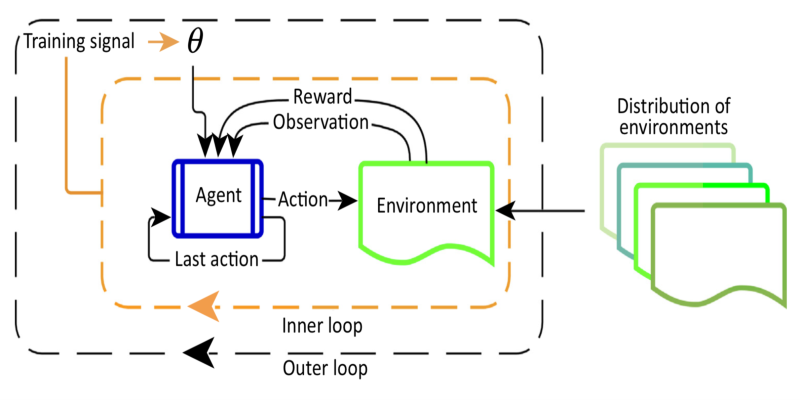
Curious about Meta-RL? Learn how meta-reinforcement learning helps data science systems adapt faster, use fewer samples, and evolve smarter—without retraining from scratch every time

How do we keep digital research accessible and citable over time? Learn how assigning DOIs to datasets and models supports transparency, reproducibility, and proper credit in modern research

How Hugging Face for Education makes AI accessible through user-friendly machine learning models, helping students and teachers explore natural language processing in AI education
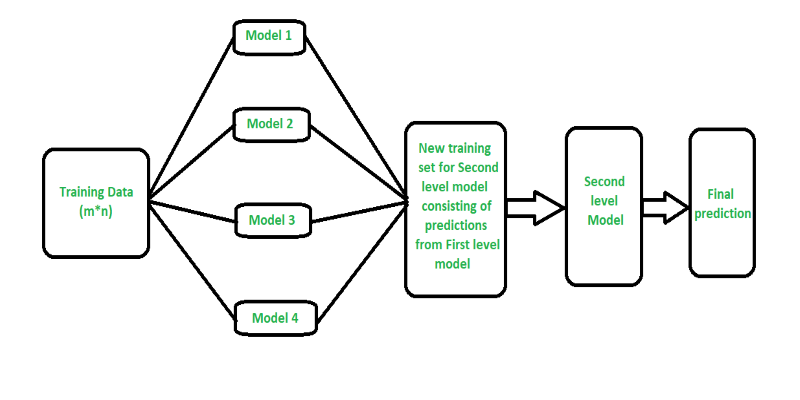
Curious how stacking boosts model performance? Learn how diverse algorithms work together in layered combinations to improve accuracy—and why stacking goes beyond typical ensemble methods