Advertisement
When businesses start collecting a lot of data, they inevitably reach a crossroads: Should all that information live in a data lake or a data warehouse? If you’ve heard both terms tossed around in meetings without a clear explanation of what sets them apart, you’re not alone. At a glance, both sound like storage solutions—and they are—but their differences go deeper than just where data is stored. Think of them more like two separate kitchens: one meticulously organized with labeled spice jars and measured ingredients, the other a pantry where everything from raw potatoes to unopened pasta sauces sits waiting for the right recipe.
So, what separates the two—and more importantly, how do you know which one’s right for your team?
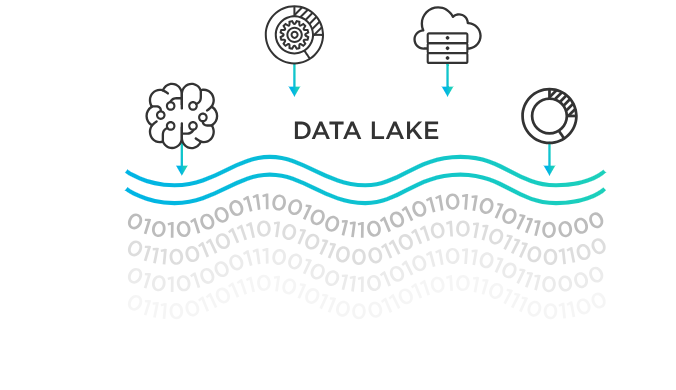
Let’s begin here because data lakes tend to throw people off. A data lake is more or less a giant storage space that doesn’t worry too much about tidiness. Structured data, unstructured data, semi-structured data—it accepts them all. Whether it’s a video file, a PDF, a database export, or a social media feed, the lake takes it as-is. That’s because it doesn’t expect you to define how you’ll use the data upfront.
This flexibility can be a big deal for businesses working with emerging tech, AI training, or anything where you want to run different kinds of analysis later. You don’t need to decide on the schema before you store data. That comes when you actually access and process it—what’s known as schema-on-read.
The other thing that sets data lakes apart is cost. Since they're designed to store large volumes of raw data at a low cost, they typically run on low-cost storage services and are built with scalability in mind. Amazon S3, Azure Data Lake, and Google Cloud Storage are a few examples. Because of this affordability, data lakes are often the go-to for companies expecting to deal with massive volumes of information over time.

Now, picture the other kitchen. Everything's labeled, nothing's out of place, and every tool is where it should be. That's the data warehouse. It doesn't accept just anything—you have to process the data before you store it. This is known as schema-on-write. It's structured, ready to be queried, and optimized for analysis.
A data warehouse is built for business intelligence tools, dashboards, and reports. It’s where sales data, transaction records, customer behavior metrics, and inventory stats live once they’ve been cleaned up. The value here lies in performance. Because the data is already refined and indexed, queries run fast. If your sales team wants to know how a campaign affected weekly revenue, they’ll get that answer without waiting.
That speed and structure come at a cost, though—literally. Data warehouses tend to be more expensive than lakes, both in terms of storage and the compute resources needed to keep them running smoothly. But they shine in scenarios where accuracy and speed matter more than flexibility.
Let’s stack them side by side. Not as a checklist, but as a clearer picture of how they operate and what they’re each best suited for.
This is the most immediate difference.
Here, the difference is about when the data is organized.
A lake is cheap. A warehouse, not so much.
This is where data warehouses usually win.
If you’re staring down a large volume of data and trying to figure out where it belongs, this isn’t about choosing a winner. It’s about picking the right setup for your specific needs. Here’s a straightforward way to get there.
Start by listing your primary data sources. Are you mainly dealing with spreadsheets, log files, CRM exports, audio recordings, or a mix of everything? If you have a lot of non-tabular content, you’re already leaning toward a lake.
Do you need this data to be cleaned and formatted before analysis? If yes, your use case might point toward a warehouse. If not, and you prefer flexibility in how the data is used later, a data lake gives you more room.
Are your teams regularly querying the data to generate reports, dashboards, or alerts? Fast performance matters here, and a warehouse delivers that. If you’re doing less frequent analysis or experimenting with data science models, the speed trade-off of a lake might be fine.
Data lakes are generally easier on the wallet and easier to expand. If cost is a concern or you expect to store petabytes down the road, lakes make sense. Just know you’ll likely need to add tools later for efficient querying.
Understanding the difference between a data lake and a data warehouse doesn’t require you to be a data engineer. It just takes clarity on what each system offers—and what your business actually needs. If your priority is storing everything in a flexible, low-cost way, the lake is where to start. If you need quick answers, structured reports, and consistent performance, the warehouse wins.
But don’t fall into the trap of thinking it’s either-or. In many cases, the best solution is to let each do what it does best and let them complement one another rather than compete.
Advertisement

How Hugging Face for Education makes AI accessible through user-friendly machine learning models, helping students and teachers explore natural language processing in AI education

Thinking of moving to the cloud? Discover seven clear reasons why businesses are choosing Google Cloud Platform—from seamless scaling and strong security to smarter collaboration and cost control
Learn what a Common Table Expression (CTE) is, why it improves SQL query readability and reusability, and how to use it effectively—including recursive CTEs for hierarchical data

Learn how to build scalable systems using Apache Airflow—from setting up environments and writing DAGs to adding alerts, monitoring pipelines, and avoiding reliability pitfalls

How Q-learning works in real environments, from action selection to convergence. Understand the key elements that shape Q-learning and its role in reinforcement learning tasks

How a course launch community event can boost engagement, create meaningful interaction, and shape a stronger learning experience before the course even starts

Should credit risk models focus on pure accuracy or human clarity? Explore why Explainable AI is vital in financial decisions, balancing trust, regulation, and performance in credit modeling

Confused about MLOps? Learn how MLflow makes machine learning deployment, versioning, and collaboration easier with real-world workflows for tracking, packaging, and serving models

Looking for practical data science tools? Explore ten standout GitHub repositories—from algorithms and frameworks to real-world projects—that help you build, learn, and grow faster in ML

How to convert transformers to ONNX with Hugging Face Optimum to speed up inference, reduce memory usage, and make your models easier to deploy across platforms
Curious about Meta-RL? Learn how meta-reinforcement learning helps data science systems adapt faster, use fewer samples, and evolve smarter—without retraining from scratch every time

How fine-tuning CLIP with satellite data improves its performance in interpreting remote sensing images and captions for tasks like land use mapping and disaster monitoring