Advertisement
When you apply for a loan, what you probably expect is a fair review based on your credit score, income, and maybe a few other details. But under the surface, there's often a complex machine learning model sifting through hundreds of variables to come up with a decision. These models have one job: to predict the risk of lending to you. But here’s where things get tricky—should these models focus on being as accurate as possible, or should they be understandable to humans? That’s where Explainable AI, or XAI, steps in.
It’s a question with real-world consequences. Financial institutions aren’t just chasing prediction scores. They're expected to make decisions they can justify. And customers? They deserve to know why their applications were accepted—or not. Let’s dig into this tension between getting things right and keeping things clear.
Think about a scenario where a model declines a credit application. Now, if the lender can’t explain why, they’re in trouble—regulatory, reputational, and sometimes legal. Interpretability isn’t optional here.
For regulated sectors like finance, explanations are more than nice-to-haves. The Equal Credit Opportunity Act, for example, requires lenders to provide a clear reason when rejecting an applicant. A decision that boils down to “our neural network said so” won’t cut it.
But interpretability goes deeper than compliance. Credit models affect people's lives. A vague, unexplained "no" can erode trust. Worse, if models carry hidden bias (and they often do), a lack of interpretability can leave it unchecked. It's like driving a fast car with fogged-up windows—you’ll move quickly, but you won’t know what you’re about to hit.
On the other side of the fence, you’ve got accuracy. And let’s be honest—it's tempting. Deep learning models, gradient boosting machines, and ensemble techniques can crunch insane volumes of data to deliver spot-on predictions.
Why wouldn’t a bank want that? Say you build a model that’s 96% accurate at predicting default. That means fewer losses, tighter risk management, and better profitability. But here’s the tradeoff: that 96% model may be too complex to explain.
Even tools like SHAP (SHapley Additive exPlanations) or LIME (Local Interpretable Model-agnostic Explanations), which aim to pull back the curtain, often create explanations that are more math than message. They might work for data scientists, but for regulators or everyday users, it can still feel like reading a foreign language.

So what do many institutions do? They compromise. They often end up using slightly less accurate models (like logistic regression) simply because those models are easier to interpret and explain. A 91% accuracy rate with full transparency may be more attractive than 96% wrapped in mystery.
The sweet spot lies somewhere in the middle—but reaching it takes more than plugging in a tool. It starts at the design phase.
Before any modeling begins, teams must agree: how much interpretability is needed? For high-stakes decisions, the bar is higher. If the model’s output will be disclosed to applicants or regulators, it must be easy to explain. On the other hand, if the model is for internal flagging or portfolio analysis, complexity may be more acceptable.
Not every problem needs deep learning. Credit scoring often involves structured data—think income levels, payment history, and age of accounts. For these problems, decision trees, linear models, or rule-based systems can often perform just as well without sacrificing transparency.
If more complex methods are needed, they must come with robust interpretability layers. That means investing in post-hoc explanation tools and validating that these explanations actually make sense to non-technical users.
It's common to run accuracy metrics—AUC, F1 score, and precision. But interpretability needs its own evaluation. How many features contribute significantly to the model's decision? Can the explanation be reduced to a sentence? Can non-technical stakeholders repeat the reason after hearing it once?
User testing helps here. Have real customer service reps or compliance officers interact with explanations. If they’re confused or misled, you’ve still got work to do.
A model that was interpretable when first deployed can drift. If the underlying data changes or features are updated, so does the clarity. Regular reviews ensure the explanations still align with business and ethical standards.
There’s an assumption that you always have to give up accuracy to gain interpretability. But that’s not always true.
Sometimes, the more complex model only marginally improves performance, say from 94% to 94.6%. In that case, you may be adding layers of opacity for very little gain. In others, you may find that your simpler model performs almost identically, especially when the data is clean and the variables are highly predictive.
Another interesting point: interpretability can actually improve accuracy over time. By understanding why a model makes certain decisions, data scientists can spot flawed assumptions, identify underrepresented groups, and refine feature engineering. So while you might start off with a tradeoff, the right feedback loop can lead to models that are both accurate and explainable.
In credit-related AI, you don’t get to pick just one side—accuracy or interpretability. You need both. But you also need a clear-headed strategy for when to lean into one and when to balance it against the other.
Explainable AI isn’t about dumbing things down. It’s about making sure people—whether customers, regulators, or employees—can understand the logic behind life-changing decisions. That doesn’t mean sacrificing performance. It just means designing models with eyes wide open, knowing that being right isn’t enough if no one can follow your reasoning.
Advertisement
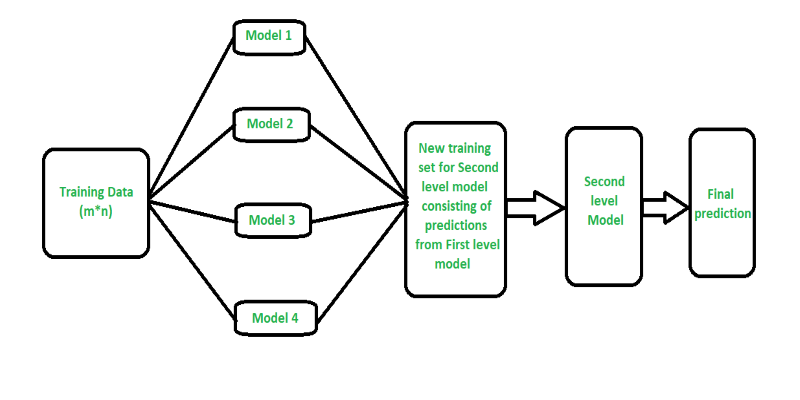
Curious how stacking boosts model performance? Learn how diverse algorithms work together in layered combinations to improve accuracy—and why stacking goes beyond typical ensemble methods
Explore how Neo4j uses graph structures to efficiently model relationships in social networks, fraud detection, recommendation systems, and IT operations—plus a practical setup guide

How Q-learning works in real environments, from action selection to convergence. Understand the key elements that shape Q-learning and its role in reinforcement learning tasks

A detailed look at training CodeParrot from scratch, including dataset selection, model architecture, and its role as a Python-focused code generation model

Learn how to build scalable systems using Apache Airflow—from setting up environments and writing DAGs to adding alerts, monitoring pipelines, and avoiding reliability pitfalls

How do we keep digital research accessible and citable over time? Learn how assigning DOIs to datasets and models supports transparency, reproducibility, and proper credit in modern research

Curious why developers are switching from Solidity to Vyper? Learn how Vyper simplifies smart contract development by focusing on safety, predictability, and auditability—plus how to set it up locally

Curious about how to start your first machine learning project? This beginner-friendly guide walks you through choosing a topic, preparing data, selecting a model, and testing your results in plain language
Learn what a Common Table Expression (CTE) is, why it improves SQL query readability and reusability, and how to use it effectively—including recursive CTEs for hierarchical data

Curious what’s really shaping AI and tech today? See how DataHour captures real tools, honest lessons, and practical insights from the frontlines of modern data work—fast, clear, and worth your time

Learn how Apache Oozie coordinates Hadoop jobs with XML workflows, time-based triggers, and clean orchestration. Ideal for production-ready data pipelines and complex ETL chains

How a course launch community event can boost engagement, create meaningful interaction, and shape a stronger learning experience before the course even starts