Advertisement
We’re surrounded by connections—some obvious, others more intricate. Whether it’s friendships on social media, product recommendations, or supply chains, relationships drive behavior. Traditional databases weren’t built to handle these webs efficiently. That’s where Neo4j steps in—not as a replacement for structured data systems, but as a natural fit when relationships are at the center.
While many systems treat relationships as side notes—foreign keys buried in static tables—Neo4j treats them with equal importance as the data points themselves. That shift changes how we store, retrieve, and think about connected data.
At its core, Neo4j is built around graph theory. Data points are modeled as nodes, and their relationships—like "FRIENDS_WITH" or "PURCHASED"—are actual data, not just references. Each element, whether a node or a relationship, can have its properties, creating a highly expressive structure that mirrors real-world complexity.
This setup allows you to follow paths in the data the way you’d naturally think—like drawing lines between people and their shared interests—rather than wrestling with joins and nested queries.
Neo4j uses Cypher, a pattern-based language that reads more like a description than a command. For example, to find all friends of someone named Emma who live in Paris:
cypher
CopyEdit
MATCH (e:Person {name: "Emma"})-[:FRIENDS_WITH]->(friend:Person)-[:LIVES_IN]->(city:City {name: "Paris"})
RETURN friend
Instead of layering subqueries and sorting through joins, you simply match patterns—like sketching out a mini-network that the engine can follow.
Graphs can model anything. But Neo4j really stands out when the data isn’t just a list of entries, but a web of connections. Here are four areas where that advantage becomes obvious.
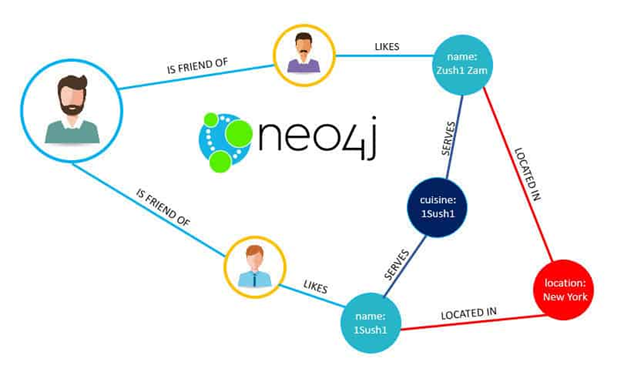
Every platform built around people and their interactions fits naturally into a graph. You’re not just storing who someone is—you’re tracking who they know, what they like, and how those things connect. Neo4j makes it easy to trace that web quickly and at scale.
Want to recommend someone people might know? Or map out a user's influence? These queries are smooth in Neo4j because the data model matches the use case from the start.
Suggestions based on user behavior work best when you understand patterns, not just who bought what, but who also liked similar things or followed certain trends. Neo4j helps build that kind of logic without needing to flatten it into categories.
Here, you’re not just filtering by shared tags or scores. You’re looking at movement—what users with similar histories do next—and predicting behavior through proximity in the graph.
Suspicious activity often hides in patterns that don’t appear obvious at first glance. It’s not just about a single transaction—it’s about clusters of behavior: linked accounts, shared devices, repeated transfers. Neo4j reveals these links quickly by exposing how data points are connected behind the scenes.
You can track paths between accounts, identify strange loops, or see if a transaction was just one of many that followed a known suspicious trail—all within a single query.
Large IT environments include dozens (or hundreds) of components relying on each other. Servers, databases, APIs, backups—they all have relationships. Graph databases turn these from static diagrams into systems you can query and monitor.
If one node goes down, what’s impacted? If you need to scale something, what else is affected? Neo4j makes it simple to trace these paths without digging through spreadsheets or outdated docs.
What makes Neo4j fast and scalable isn’t just how it models data, but how it stores and processes it.
Neo4j uses a native graph engine, which means it doesn’t sit on top of a relational or document database. It stores nodes and relationships directly. The key feature here is index-free adjacency—each node contains direct pointers to related nodes. This allows for constant-time traversal, even across massive datasets.
Even though Neo4j handles unstructured, relationship-heavy data, it doesn’t cut corners on reliability. It supports ACID properties, ensuring your data remains consistent and safe, even during concurrent operations or system interruptions.
Neo4j supports Causal Clustering, a model where leader nodes handle writes and follower nodes handle reads. This setup allows you to scale efficiently, distributing load across servers without sacrificing performance or consistency. The system stays available and durable, even when parts of it go offline.
Curious about trying Neo4j for yourself? Here’s how you can begin exploring without much setup.
Choose your preferred method:
Each of these gives you access to Neo4j’s browser tool for visual interaction.
Start small. Here’s a basic graph that models two people and their connection:
cypher
CopyEdit
CREATE (a:Person {name: "Alice"})
CREATE (b:Person {name: "Bob"})
CREATE (a)-[:FRIENDS_WITH]->(b)
You’ve just created two nodes and a relationship. You’ll see the result instantly in the Neo4j visual browser.
Now, retrieve Bob using a simple match:
cypher
CopyEdit
MATCH (a:Person {name: "Alice"})-[:FRIENDS_WITH]->(friend)
RETURN friend
This pattern will return any person Alice is connected to via a FRIENDS_WITH relationship.
Once you’re comfortable, load real data using Neo4j’s import tools or Cypher-based ingestion. The structure you’ve already built scales naturally—no need to remodel just because the dataset grows.
Neo4j doesn't approach data as a pile of entries to be retrieved. It sees it as a set of meaningful links. And when those links matter more than isolated facts, graphs become not just useful, but essential.
Whether you're building a social feature, catching fraud, managing IT networks, or creating smarter recommendations, Neo4j helps surface the connections hiding inside your data. And the best part? The system doesn’t make you fight to see them. If your problems are rooted in how things relate—not just what they are—Neo4j offers a structure that actually makes sense.
Advertisement

Should credit risk models focus on pure accuracy or human clarity? Explore why Explainable AI is vital in financial decisions, balancing trust, regulation, and performance in credit modeling
Learn what a Common Table Expression (CTE) is, why it improves SQL query readability and reusability, and how to use it effectively—including recursive CTEs for hierarchical data

Discover lesser-known Pandas functions that can improve your data manipulation skills in 2025, from query() for cleaner filtering to explode() for flattening lists in columns

How Margaret Mitchell, one of the most respected machine learning experts, is transforming the field with her commitment to ethical AI and human-centered innovation

Explore how Google Cloud Platform (GCP) powers scalable, efficient, and secure applications in 2025. Learn why developers choose GCP for data analytics, app development, and cloud infrastructure

Is your team using AI tools you don’t know about? Shadow AI is growing inside companies fast—learn how to manage it without stifling innovation or exposing your data
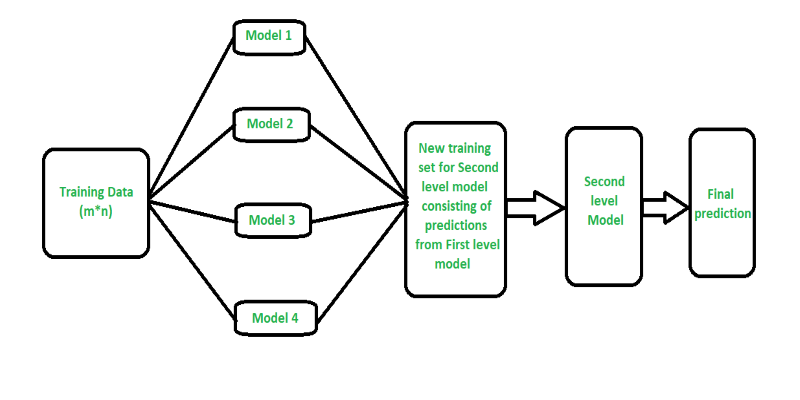
Curious how stacking boosts model performance? Learn how diverse algorithms work together in layered combinations to improve accuracy—and why stacking goes beyond typical ensemble methods
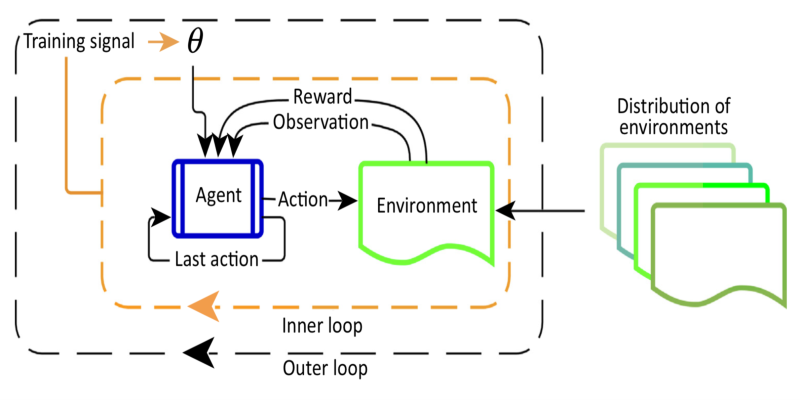
Curious about Meta-RL? Learn how meta-reinforcement learning helps data science systems adapt faster, use fewer samples, and evolve smarter—without retraining from scratch every time

How do we keep digital research accessible and citable over time? Learn how assigning DOIs to datasets and models supports transparency, reproducibility, and proper credit in modern research

Thinking of moving to the cloud? Discover seven clear reasons why businesses are choosing Google Cloud Platform—from seamless scaling and strong security to smarter collaboration and cost control

Curious about how to start your first machine learning project? This beginner-friendly guide walks you through choosing a topic, preparing data, selecting a model, and testing your results in plain language

Learn how Apache Oozie coordinates Hadoop jobs with XML workflows, time-based triggers, and clean orchestration. Ideal for production-ready data pipelines and complex ETL chains