Advertisement
Let’s start with something simple: building machine learning models isn’t the hard part anymore. You can whip up a basic model in minutes with the right data and a good notebook. But getting that model out of your local machine and into the hands of real users? That’s where things usually get messy. This is where MLOps steps in, and tools like MLflow make all the difference. Instead of managing a jungle of scripts, manual logs, and post-it notes about which version of the model worked best, MLflow brings in structure without forcing you to relearn everything you already know.
Most machine learning workflows look great during experimentation. You tweak your hyperparameters, run a few metrics, and before you know it, you've got a decent accuracy score. But then comes the chaos:
MLOps, short for Machine Learning Operations, is a way to move from experiments to dependable deployments. It blends practices from software engineering (like CI/CD) with the unique demands of machine learning, such as retraining, monitoring for drift, and versioning of both data and models.
MLflow doesn’t try to do everything at once. And that’s actually its strength. It gives you four core components that work independently but play well together:
Let’s break it down step-by-step with an actual workflow, so you see where MLOps really kicks in.
You start with your data and model. Maybe it's a scikit-learn pipeline, maybe it’s TensorFlow. Either way, MLflow Tracking lets you plug in a single line of code to start logging:
python
CopyEdit
import mlflow
with mlflow.start_run():
mlflow.log_param("alpha", 0.01)
mlflow.log_metric("rmse", 0.87)
From there, every parameter tweak, training metric, and artifact—whether it’s a confusion matrix or a pickled model—gets logged automatically. You get a dashboard where all your runs are recorded, searchable, and comparable. No more asking, "What changed between version_3_final and version_3_final_final?"
Now, if someone else on your team wants to try a new approach, they don’t start from scratch. They just clone the existing run, adjust what they need, and all of it stays traceable.
Let's say your model was great, but only on your machine. That's not good enough. You need a way to ship that experiment so others can reproduce the result. This is where MLflow Projects steps in.
You organize your code into a standard format with a YAML file that tells MLflow what command to run, what environment to use, and what parameters to expect. Whether you're using conda or virtualenv, MLflow can automatically recreate the environment.
Here’s a quick example of an ML project file:
yaml
CopyEdit
name: regression_model
conda_env: conda.yaml
entry_points:
main:
parameters:
alpha: {type: float, default: 0.1}
command: "python train.py --alpha {alpha}"
You now have something that behaves consistently on every machine. When another team member wants to test it, they don’t ask questions about dependencies—they just run the project. Simple.
By the time you’ve got a model that works, you're probably sitting on a handful of different versions. Some are good on test data, some on production samples, and a few were just bad experiments. Rather than keeping them in a folder named “models_important”, MLflow Models and Registry keep things orderly.

You log your model like this:
python
CopyEdit
mlflow.sklearn.log_model(model, "model")
Then, push it to the registry:
python
CopyEdit
mlflow.register_model("runs:/
From there, you get version control, stage transitions (like “Staging” or “Production”), and the ability to add comments, tags, and descriptions. Everyone knows which model is the production model and which one is just being evaluated.
This structure helps teams avoid common slip-ups like pushing the wrong model into production or retraining using outdated datasets. And because it’s all recorded, audit trails are built-in.
Getting your model into production often feels like a totally different project. But MLflow’s deployment capabilities simplify this.
If you're deploying locally or for testing, MLflow can serve the model as a REST API with a one-liner:
bash
CopyEdit
mlflow models serve -m models:/ChurnPredictionModel/Production
It automatically handles input/output serialization and allows you to test integrations quickly. For cloud deployment, MLflow supports tools like Azure ML, SageMaker, or even Kubernetes.
Once in production, you can log predictions, monitor model performance, and set up alerts when things go off track. MLflow doesn’t force a specific monitoring stack, but it plays well with existing logging tools so that performance monitoring feels less like guesswork and more like an actual system check.
MLOps is what separates half-baked experiments from machine learning that actually does something in the real world. It’s the guardrails, the audit trail, and the shared language between data scientists and engineers. MLflow doesn’t try to reinvent your workflow—it just fills in the gaps where traditional tools fall short.
It logs what you might forget, packages what you’d otherwise leave undocumented, and tracks what would normally get overwritten. And in doing so, it clears up the chaos that creeps in once you move beyond the training script. If you’re dealing with more than one model or working with more than one person, MLflow is worth putting into your setup. Not because it's flashy, but because it keeps things from falling apart.
Advertisement

How Stable Diffusion in JAX improves speed, scalability, and reproducibility. Learn how it compares to PyTorch and why Flax diffusion models are gaining traction
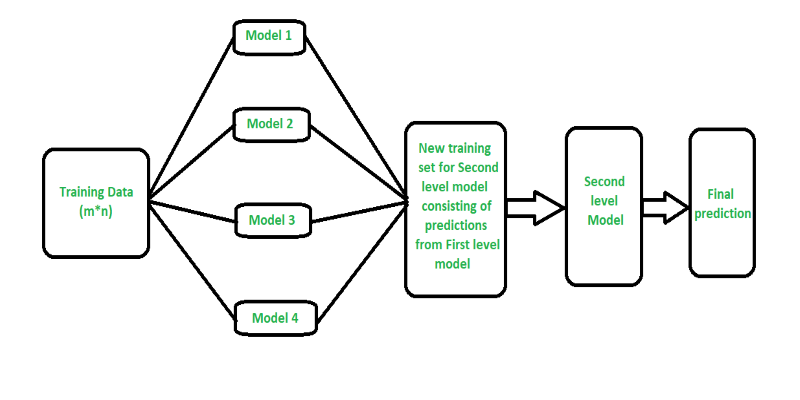
Curious how stacking boosts model performance? Learn how diverse algorithms work together in layered combinations to improve accuracy—and why stacking goes beyond typical ensemble methods

Confused about the difference between a data lake and a data warehouse? Discover how they compare, where each shines, and how to choose the right one for your team

How fine-tuning CLIP with satellite data improves its performance in interpreting remote sensing images and captions for tasks like land use mapping and disaster monitoring

Thinking of moving to the cloud? Discover seven clear reasons why businesses are choosing Google Cloud Platform—from seamless scaling and strong security to smarter collaboration and cost control

How Margaret Mitchell, one of the most respected machine learning experts, is transforming the field with her commitment to ethical AI and human-centered innovation
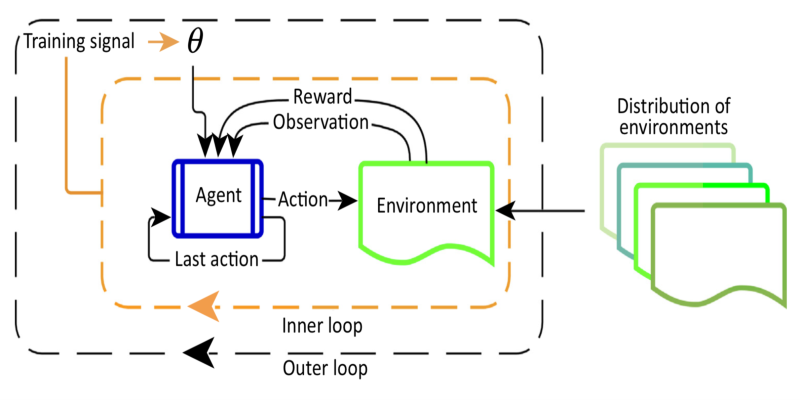
Curious about Meta-RL? Learn how meta-reinforcement learning helps data science systems adapt faster, use fewer samples, and evolve smarter—without retraining from scratch every time

New to YARN? Learn how YARN manages resources in Hadoop clusters, improves performance, and keeps big data jobs running smoothly—even on a local setup. Ideal for beginners and data engineers

How to convert transformers to ONNX with Hugging Face Optimum to speed up inference, reduce memory usage, and make your models easier to deploy across platforms

How does HDFS handle terabytes of data without breaking a sweat? Learn how this powerful distributed file system stores, retrieves, and safeguards your data across multiple machines

Learn how to build scalable systems using Apache Airflow—from setting up environments and writing DAGs to adding alerts, monitoring pipelines, and avoiding reliability pitfalls

Learn how Apache Oozie coordinates Hadoop jobs with XML workflows, time-based triggers, and clean orchestration. Ideal for production-ready data pipelines and complex ETL chains