Advertisement
In academic publishing, the DOI has long been a dependable way to label and locate research papers. It gives each item a stable identity, ensuring it can always be found, even years later. But research today is more than just papers. It includes datasets, models, scripts, and tools.
These parts often go untracked, lost in broken links or unclear versions. Assigning DOIs to datasets and models helps address that. It offers a practical way to cite, share, and preserve digital work. More than a technical fix, it supports transparency, traceability, and recognition in digital research.
A Digital Object Identifier (DOI) is a unique string assigned to digital content, typically used for journal articles. It provides a fixed link, regardless of where the content is hosted. This ensures that the work is easy to find and cite, helping keep academic communication stable and organized.
DOIs have served well for text-based publications, but the scope of scholarly output has changed. Researchers now share datasets, trained models, scripts, and more. These materials are critical for understanding and replicating results, yet they often lack proper identifiers. Files may be hosted temporarily, renamed, or updated without a clear record. Without persistent links, much of this digital work becomes hard to access or verify.
Applying DOIs to datasets and models fixes this. It lets others reliably cite a specific version. This adds accountability and encourages better data and model-sharing practices. As more research relies on digital tools, the need for consistent tracking grows.
When a DOI is assigned to a dataset or model, it’s backed by metadata registered with organizations like DataCite or Crossref. This metadata typically includes the title, author names, creation date, version number, and licensing details. The object is hosted on a platform that supports DOI resolution, such as Zenodo, Figshare, or an academic repository.

This process does more than just assign a number. It makes the dataset or model a formal, traceable research object. Future users can cite it accurately, access the same version, and review the associated metadata. If the dataset or model is updated, a new DOI can be created, preserving older versions. This prevents confusion over which version was used in a study.
In machine learning, models are often reused and fine-tuned. A DOI anchors a particular version and ties it to performance data, training inputs, or evaluation metrics. This is especially useful when the model appears in multiple papers or across platforms.
With datasets, the benefit is similar. For example, a team studying satellite images might publish their dataset on a repository that issues DOIs. Anyone using it can cite the dataset directly, ensuring their work builds on the same version. Over time, this improves clarity and reproducibility across studies.
Assigning DOIs to datasets and models improves reproducibility. Often, researchers reference a dataset or model that’s either no longer available or was updated without clear documentation. A DOI ensures that others can access the exact resource used, regardless of when the paper was published.
This reliability supports accountability. Being able to trace results back to the original dataset or model lets others review, audit, or build upon previous work. If biases or errors are discovered, it’s easier to pinpoint where they came from.
DOIs also help give credit where it’s due. Datasets and models can be time-intensive to develop, and they deserve proper recognition. When cited with a DOI, the contributors’ work becomes visible in citation counts and reference lists. This visibility can influence career development, funding opportunities, and overall recognition within a field.
Repositories that issue DOIs often require a baseline of documentation, which leads to better-organized data. These platforms offer hosting, metadata fields, and long-term access. For researchers, this reduces the hassle of managing links and helps standardize how digital assets are shared.
In machine learning, pairing DOIs with model cards or datasheets adds another layer of context. A model with a DOI can link to its known limitations, performance benchmarks, or intended use cases. This prevents misuse and helps others apply the model more responsibly.
Despite clear benefits, several challenges remain. One is cultural. Many researchers still treat datasets and models as side products, not as formal research outputs. Assigning a DOI might feel unnecessary or time-consuming without a shift in how value is perceived in digital contributions.
Technical barriers can also get in the way. Some projects store their data or models on servers that don't support DOI assignments. Moving these to appropriate platforms can involve added steps, especially in institutions with limited support for open data infrastructure.
Deciding how granular DOIs should be is another issue. Should every minor model tweak or dataset version get a new DOI? What if someone reuses a portion of a dataset? These are questions without fixed answers yet, and they’re the subject of ongoing discussion among librarians, funders, and data repositories.
Still, things are changing. Open science initiatives, such as FAIR (Findable, Accessible, Interoperable, Reusable), encourage the use of persistent identifiers for all research outputs. Journals and funding agencies increasingly recommend or require DOI-backed sharing of data and models.
In the future, research papers may include clear citation chains linking to models and datasets through DOIs. This would improve transparency, showing how results were produced, which tools were used, and where the inputs came from. It would support more thoughtful reuse of digital resources across disciplines.
The DOI system once used almost exclusively for research papers, is now being extended to digital assets such as datasets and models. As research becomes more dependent on these components, the need for stable, citable links grows. DOIs offer a practical solution—making digital work easier to track, verify, and credit. This shift brings structure to areas of research that have been loosely managed until now. It helps ensure that digital contributions are treated seriously and preserved over time. By applying DOIs more broadly, we support better science: reproducible, open, and built on clear foundations.
Advertisement

Curious why developers are switching from Solidity to Vyper? Learn how Vyper simplifies smart contract development by focusing on safety, predictability, and auditability—plus how to set it up locally

How does HDFS handle terabytes of data without breaking a sweat? Learn how this powerful distributed file system stores, retrieves, and safeguards your data across multiple machines

New to YARN? Learn how YARN manages resources in Hadoop clusters, improves performance, and keeps big data jobs running smoothly—even on a local setup. Ideal for beginners and data engineers
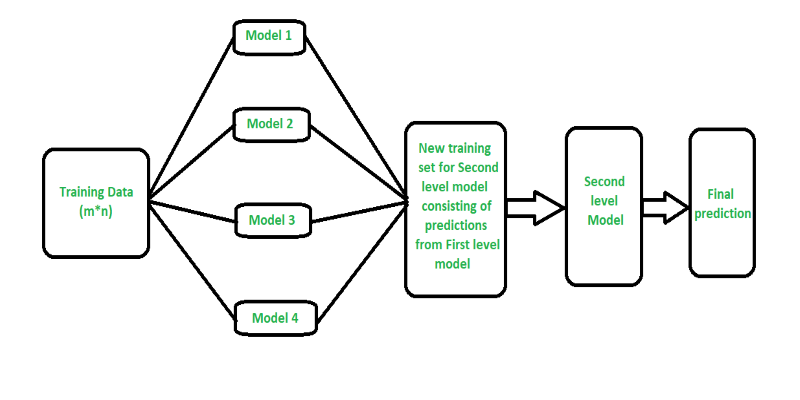
Curious how stacking boosts model performance? Learn how diverse algorithms work together in layered combinations to improve accuracy—and why stacking goes beyond typical ensemble methods

How the Annotated Diffusion Model transforms the image generation process with transparency and precision. Learn how this AI technique reveals each step of creation in clear, annotated detail

Thinking of moving to the cloud? Discover seven clear reasons why businesses are choosing Google Cloud Platform—from seamless scaling and strong security to smarter collaboration and cost control

How Q-learning works in real environments, from action selection to convergence. Understand the key elements that shape Q-learning and its role in reinforcement learning tasks

Looking for practical data science tools? Explore ten standout GitHub repositories—from algorithms and frameworks to real-world projects—that help you build, learn, and grow faster in ML

Curious what’s really shaping AI and tech today? See how DataHour captures real tools, honest lessons, and practical insights from the frontlines of modern data work—fast, clear, and worth your time

Discover lesser-known Pandas functions that can improve your data manipulation skills in 2025, from query() for cleaner filtering to explode() for flattening lists in columns
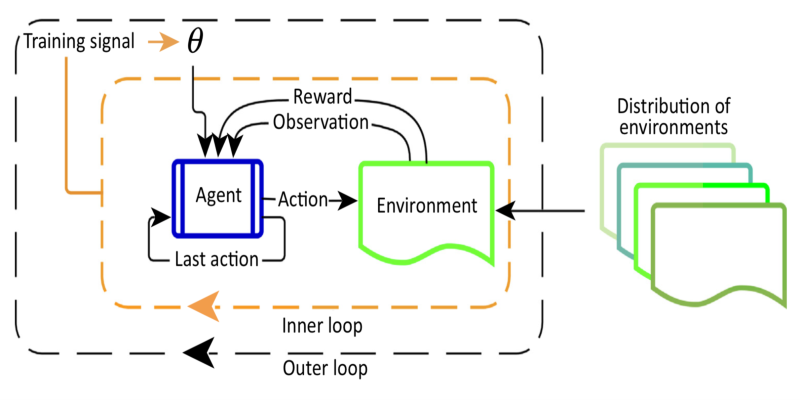
Curious about Meta-RL? Learn how meta-reinforcement learning helps data science systems adapt faster, use fewer samples, and evolve smarter—without retraining from scratch every time

How fine-tuning CLIP with satellite data improves its performance in interpreting remote sensing images and captions for tasks like land use mapping and disaster monitoring