Advertisement
Machine learning isn’t just about throwing one model at a problem and hoping it sticks. Often, the best results come from layering models in clever ways — and that’s where stacking comes in. While it's tempting to think of stacking as just another ensemble technique, it's actually a thoughtful process of combining predictions from multiple models to produce better outcomes than any of them could achieve alone.
Let’s get straight to it: stacking is less about picking the "right" model and more about arranging several that can cover for each other’s weaknesses. That’s the beauty of it — you don’t have to rely on a single viewpoint when you can combine several. And when it's done right, stacking can significantly boost predictive accuracy.
Before diving into specific algorithms, it helps to get clear on what stacking actually is — and what it isn’t. Unlike bagging or boosting, which mostly rely on iterations of the same type of model (think multiple decision trees), stacking blends different models together. The idea is simple: let several base learners make predictions, and then train a higher-level model — often called a meta-learner — to combine those predictions into a final result.
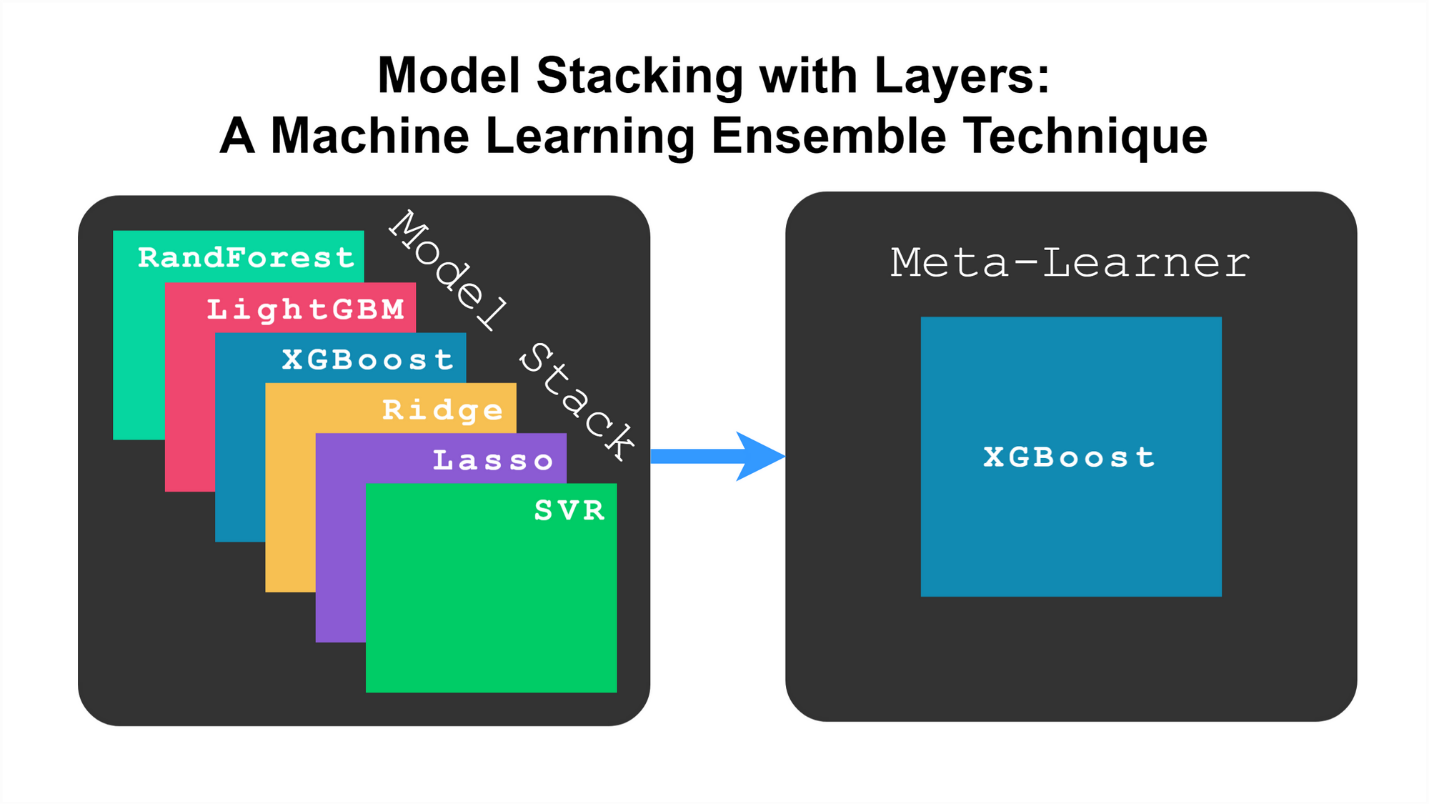
The trick is in how well these base models complement each other. A good stack involves diverse models — linear, tree-based, and perhaps even neural — because variety helps cover more ground.
This is a classic stack for structured datasets. It works well because each component brings something different to the table:
In practice, this kind of stack is straightforward. You train all three on the same training set, collect their outputs (either predicted probabilities or class labels), and feed them into another model — often a logistic regression again — that learns how to combine them into one final prediction. It’s surprisingly effective, especially on classification tasks where no single model stands out.
This combination tends to do well in text classification problems, and here’s why:
Each model predicts on the validation folds during training, and their predictions become features for the meta-model — maybe another SVM or even a simple ridge regression. The result is a composite that can make sense of text in ways a single model rarely can.
When you’re dealing with structured numeric data and you want sheer predictive power, this stack often delivers.
These models tend to disagree in useful ways, which is exactly what stacking needs. By letting each model specialize and then letting a meta-learner smooth out the differences, the stack captures more nuance than any one algorithm on its own.
In deep learning circles, stacking takes a different shape, but the idea stays the same. Instead of mixing basic models, you mix architectures.
When working with multi-modal inputs (say, a dataset with text and images), combining these models makes sense. You process each modality through its suitable network, and then you stack the outputs — usually dense representations — into a final feed-forward network that handles the decision-making.
It’s more resource-intensive, yes. But for problems like caption generation or sentiment detection with images, the performance boost is often worth the extra compute.
This trio is great for tabular data where features might include categorical variables, engineered numerical features, and interaction terms.
This stack tends to be robust, especially when your data is messy or irregular. The neural network fills in gaps left by the tree-based models, and the CatBoost model gives stability where categories are concerned.
If you’re looking to build your own stacking model — regardless of which algorithms you use — the steps are generally the same:
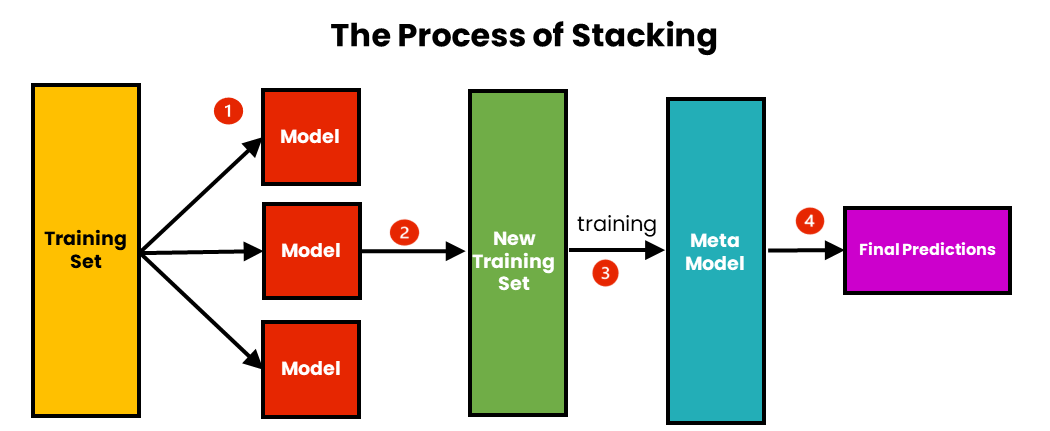
You’ll need training data for the base learners, a separate validation set to generate their predictions, and a test set to evaluate the final model.
Pick a few diverse models. Train them on the training set. Then, use these models to predict on the validation set. These predictions become the inputs for your next model.
Each base learner's output becomes a feature. For example, if you have three base models and a binary classification problem, you’ll end up with three prediction columns.
Now, use the prediction features to train another model — your meta-learner — on the validation set. This model learns how to best combine the predictions of the base models.
When you're ready to test, first generate base-model predictions for the test set, feed them to the meta-model, and then make your final prediction.
Stacking isn't magic — it's just smart engineering. The real win comes from understanding that different algorithms see data differently. By letting each of them make a case and then combining their viewpoints, you can end up with a model that's far more accurate than any individual one.
The hard part isn't the stacking itself. It's in choosing which models to include and making sure they don't all agree, because if they do, you've just added complexity without any gain. But if you get it right? Stacking can quietly become the secret weapon behind your model's surprising accuracy.
Advertisement

Learn how to build scalable systems using Apache Airflow—from setting up environments and writing DAGs to adding alerts, monitoring pipelines, and avoiding reliability pitfalls

How Margaret Mitchell, one of the most respected machine learning experts, is transforming the field with her commitment to ethical AI and human-centered innovation

New to YARN? Learn how YARN manages resources in Hadoop clusters, improves performance, and keeps big data jobs running smoothly—even on a local setup. Ideal for beginners and data engineers

Is your team using AI tools you don’t know about? Shadow AI is growing inside companies fast—learn how to manage it without stifling innovation or exposing your data

A detailed look at training CodeParrot from scratch, including dataset selection, model architecture, and its role as a Python-focused code generation model

How Stable Diffusion in JAX improves speed, scalability, and reproducibility. Learn how it compares to PyTorch and why Flax diffusion models are gaining traction

Thinking of moving to the cloud? Discover seven clear reasons why businesses are choosing Google Cloud Platform—from seamless scaling and strong security to smarter collaboration and cost control

Should credit risk models focus on pure accuracy or human clarity? Explore why Explainable AI is vital in financial decisions, balancing trust, regulation, and performance in credit modeling

Confused about the difference between a data lake and a data warehouse? Discover how they compare, where each shines, and how to choose the right one for your team
Curious how stacking boosts model performance? Learn how diverse algorithms work together in layered combinations to improve accuracy—and why stacking goes beyond typical ensemble methods

How fine-tuning CLIP with satellite data improves its performance in interpreting remote sensing images and captions for tasks like land use mapping and disaster monitoring

Learn how Apache Oozie coordinates Hadoop jobs with XML workflows, time-based triggers, and clean orchestration. Ideal for production-ready data pipelines and complex ETL chains