Advertisement
Pandas is a powerful Python library widely used for data manipulation and analysis. Most people are familiar with the basic functions like read_csv, head(), and groupby(). But Pandas has many lesser-known functions that can make your work easier, faster, or cleaner when dealing with data. These hidden gems often go unnoticed, yet knowing them can improve how you handle complex tasks. This article introduces some of these rarely used Pandas functions in 2025 that are worth adding to your toolbox.
Filtering rows based on a condition is common and usually done with Boolean indexing. However, query() lets you write conditions as a string expression, making your code more readable, especially with multiple conditions.
python
CopyEdit
df.query('age > 30 and income < 50000')
This function works well when your filtering involves several columns. It can also handle variable substitution inside the query string, which helps keep your code tidy.
Sometimes, a column contains lists or arrays, and you want to convert each element in those lists into separate rows. The explode() function does exactly that.
For example, if a cell has a list of tags, explode() will create a new row for each tag, repeating the other column values.
python
CopyEdit
df.explode('tags')
This is particularly useful when working with nested data or JSON imports that have list fields.
When preparing data for machine learning, categorical variables often need conversion into numeric form. Instead of writing custom code, get_dummies() automatically converts categorical columns into dummy/indicator variables.
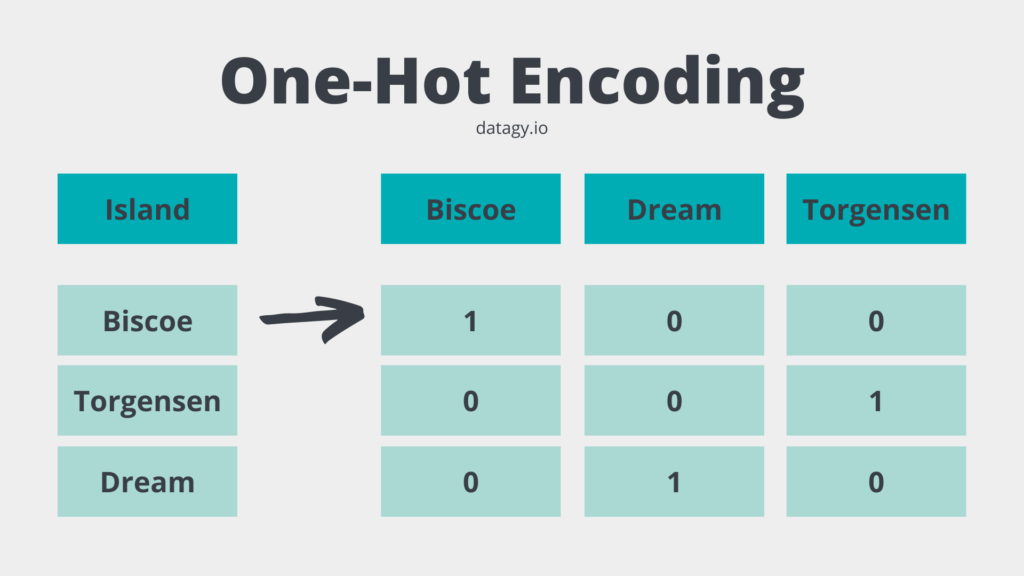
python
CopyEdit
pd.get_dummies(df['category'])
You can also apply it to the whole DataFrame and choose whether to drop one category to avoid multicollinearity.
While many know pivot(), fewer use pivot_table(), which is more powerful. It allows aggregation during pivoting, handling duplicates gracefully.
For example, you can create a table showing average sales by region and product:
python
CopyEdit
df.pivot_table(values='sales', index='region', columns='product', aggfunc='mean')
pivot_table() supports multiple aggregation functions and can fill missing values, too, making it flexible for summarizing data.
These two functions are similar but serve different purposes. mask() replaces values where a condition is true, while where() keeps values where the condition is true and replaces others.
For instance, to replace negative values with zero:
python
CopyEdit
df['column'] = df['column'].mask(df['column'] < 0, 0)
These functions offer a clear way to apply conditional changes without complex loops or lambda functions.
Rather than adding columns one by one, assign() lets you chain column creation or modification in a readable way.
python
CopyEdit
df.assign(new_col=df['old_col'] * 2, another_col=lambda x: x['new_col'] + 5)
This keeps transformations concise and readable, which is handy in data pipelines.
Pandas operations often chain together, but when you have custom functions, pipe() helps insert them smoothly.
Example:
python
CopyEdit
df.pipe(custom_function).pipe(another_function)
It improves readability by reducing nested calls and clarifying the data flow through your processing steps.
When loading data, Pandas guesses data types, but sometimes you want more precise types, like string instead of object.
Using:
python
CopyEdit
df = df.convert_dtypes()
helps Pandas select the best possible dtypes, improving performance and consistency, especially with nullable data types.
Although not a data transformation function, style lets you apply visual formatting to DataFrames in Jupyter Notebooks.
For example:
python
CopyEdit
df.style.highlight_max(axis=0)
You can highlight max values, apply color gradients, or format numbers. This helps in quickly spotting trends or anomalies during data exploration.
When working with large datasets, knowing memory usage is important. memory_usage() shows how much memory each column consumes.
python
CopyEdit
df.memory_usage(deep=True)
This lets you identify heavy columns and consider downcasting or converting types to save memory.
factorize() turns categorical values into numeric codes quickly.
python
CopyEdit
codes, uniques = pd.factorize(df['category'])
It’s faster than LabelEncoder from scikit-learn and useful when you want a simple numeric representation without external dependencies.
A newer Pandas feature allows exploding multiple list-like columns at once. This can flatten complex nested structures in fewer steps.

python
CopyEdit
df.explode(['col1', 'col2'])
This is handy for cleaning up data from APIs or files with nested arrays.
When you need to access or set a single value in a DataFrame, at[] and iat[] are faster alternatives to loc[] and iloc[].
python
CopyEdit
df.at[row_label, column_label] = new_value
python
CopyEdit
df.iat[row_index, column_index] = new_value
These are useful when performance matters and you’re working with individual cells.
By default, after exploding a list column, the index repeats old labels, which can cause confusion. Using the parameter ignore_index=True resets the index:
python
CopyEdit
df.explode('list_col', ignore_index=True)
This results in a clean DataFrame with sequential index values, making downstream operations easier.
melt() is great when you want to reshape data from wide to long format, which is common for plotting or statistical analysis.
python
CopyEdit
pd.melt(df, id_vars=['id'], value_vars=['var1', 'var2'])
This stacks selected columns into two: one for variable names and one for values, simplifying aggregation or filtering.
The functions listed here aren't usually the first ones that come to mind when working with Pandas, but they can save time and reduce code complexity. Adding them to your Pandas skill set will help you handle complex data problems more efficiently in 2025. Whether it’s cleaning nested data, managing data types, or improving code readability, these lesser-known features can make a real difference. Next time you work with data, try one of these and see how it fits your workflow.
Advertisement

How Stable Diffusion in JAX improves speed, scalability, and reproducibility. Learn how it compares to PyTorch and why Flax diffusion models are gaining traction
Explore how Neo4j uses graph structures to efficiently model relationships in social networks, fraud detection, recommendation systems, and IT operations—plus a practical setup guide

A detailed look at training CodeParrot from scratch, including dataset selection, model architecture, and its role as a Python-focused code generation model

Thinking of moving to the cloud? Discover seven clear reasons why businesses are choosing Google Cloud Platform—from seamless scaling and strong security to smarter collaboration and cost control

How to convert transformers to ONNX with Hugging Face Optimum to speed up inference, reduce memory usage, and make your models easier to deploy across platforms

How a course launch community event can boost engagement, create meaningful interaction, and shape a stronger learning experience before the course even starts

How the Annotated Diffusion Model transforms the image generation process with transparency and precision. Learn how this AI technique reveals each step of creation in clear, annotated detail

Learn how to build scalable systems using Apache Airflow—from setting up environments and writing DAGs to adding alerts, monitoring pipelines, and avoiding reliability pitfalls

New to YARN? Learn how YARN manages resources in Hadoop clusters, improves performance, and keeps big data jobs running smoothly—even on a local setup. Ideal for beginners and data engineers

How does HDFS handle terabytes of data without breaking a sweat? Learn how this powerful distributed file system stores, retrieves, and safeguards your data across multiple machines

How Q-learning works in real environments, from action selection to convergence. Understand the key elements that shape Q-learning and its role in reinforcement learning tasks
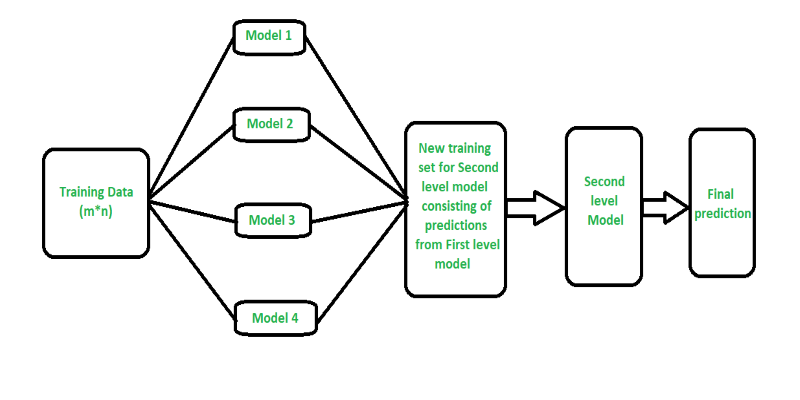
Curious how stacking boosts model performance? Learn how diverse algorithms work together in layered combinations to improve accuracy—and why stacking goes beyond typical ensemble methods