Advertisement
If you've been poking around machine learning circles long enough, you've probably heard the term "meta-learning" tossed into conversation with a half-raised eyebrow. Add reinforcement learning into the mix, and the whole thing starts sounding like something best left to academic papers. But hang on — this isn’t as dense as it sounds. Meta-reinforcement learning (Meta-RL) might be one of the more quietly useful advancements nudging data science into smarter, faster, more adaptive territory. Let’s break it down without overloading the jargon circuit.
At the heart of Meta-RL is a simple question: Can a machine learning agent learn how to learn? Traditional reinforcement learning is all about trial, error, and rewards. An agent interacts with an environment, takes actions, observes outcomes, and adjusts its behavior to maximize future rewards. The twist with Meta-RL? Instead of learning just one task, the system is trained across many tasks so it can quickly adapt to new ones, using what it has learned about learning itself.
Think of it like this: standard RL is someone learning to play one video game really well. Meta-RL is that same person playing a dozen games across different genres — platformers, puzzle games, shooters — and picking up strategies that help them adapt fast when dropped into an entirely new game.
The value in data science? Adaptability. The data never stays the same for long, and models that can't flex to new inputs, tasks, or objectives quickly become obsolete.
Data science isn't just about building one good model and calling it a day. It's about ongoing analysis, changing data sources, shifting goals, and recurring questions that often need different answers every time. In short, volatility is baked in.
Meta-RL fits because it doesn’t start from scratch every time a task changes. It generalizes patterns from previously seen tasks, learning strategies that apply beyond any one dataset or situation.
One of the thorns in the side of data science is sample efficiency — getting good results without drowning in labeled data. Meta-RL improves sample efficiency because it doesn’t need to explore every possible path anew. If it's already learned how to approach similar problems, it can make smart decisions earlier in the process.
When you're building models that constantly need tweaking — because the business question shifts, the customer behavior pivots, or the sensors start feeding different types of input — traditional models need retraining. Meta-RL offers a shortcut. Instead of rebuilding, you re-aim. It fine-tunes rather than resets.
To get a solid grasp on how meta-reinforcement learning works, it’s helpful to go through its basic structure step by step.
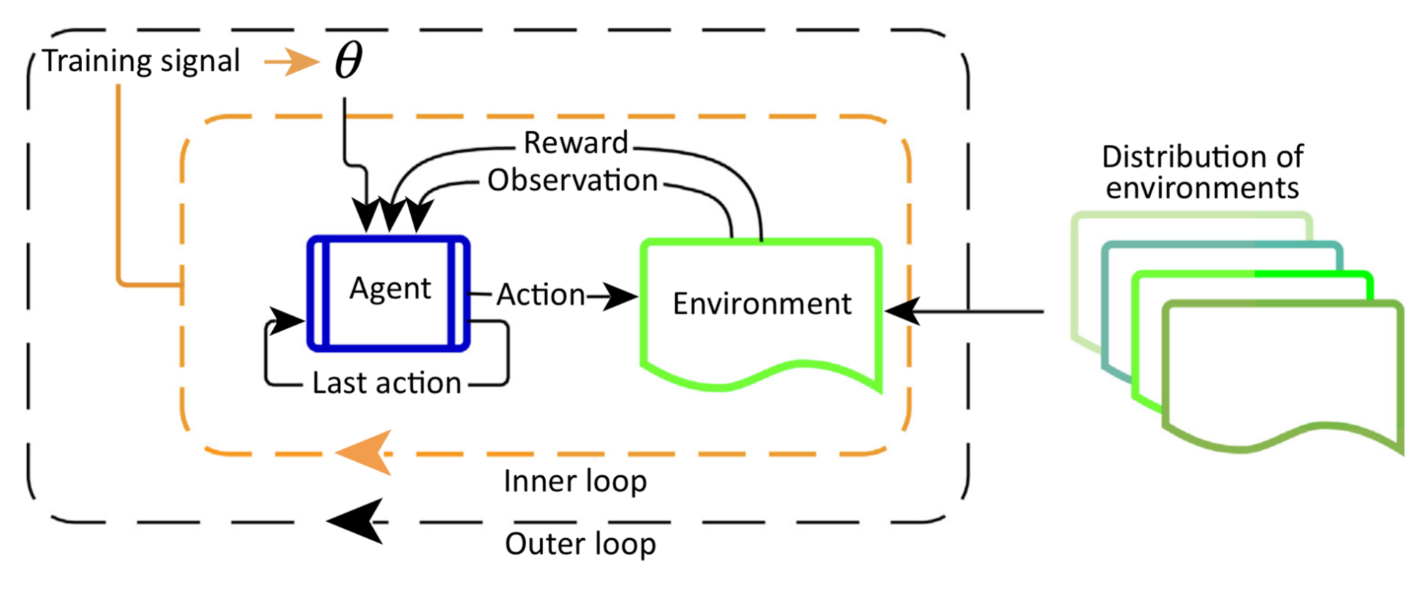
During training, the Meta-RL model is exposed to a variety of related tasks. For example, one might involve predicting outcomes in an environment where rewards are delayed, while another might require short-term gains. The important point here is that these tasks share structure — they're different, but not wildly unrelated.
This helps the model extract the meta-policy — strategies for learning itself, rather than a solution to any one problem.
Instead of just figuring out which actions work best in a specific environment, the agent is optimizing for adaptability. It’s asking, “What internal model will let me quickly learn how this new environment behaves?”
This internal model usually takes the form of a recurrent neural network (RNN). Unlike feed-forward networks that work on one input at a time, RNNs have memory. They process sequences and retain information from past actions and rewards, making them ideal for adapting behavior on the fly.
Now, drop this trained agent into a brand-new task it hasn’t seen before — say, a new environment with slightly tweaked dynamics. Here’s where Meta-RL shows its strength. Instead of randomly trying everything or going through a fresh round of slow learning, the agent uses its past learning strategy. It identifies patterns, leverages what it already knows, and converges to a good solution faster than a traditional agent.
Some systems go a step further and keep the meta-policy flexible. As more tasks come in, the agent refines its internal strategies. This allows for even more nuanced adaptation, especially in fields like recommendation systems, real-time decision making, and dynamic pricing, where patterns change quickly, and reacting late is as bad as not reacting at all.
Let’s talk practicality. It’s easy to talk about agents and environments in the abstract, but what does Meta-RL actually do in day-to-day data science workflows?
In time series forecasting, traditional models often struggle with regime shifts — changes in underlying trends. With Meta-RL, models can recognize and adapt to these shifts based on previous patterns of change, rather than treating each time step as a wholly independent entity.
Users don’t behave the same way every day. Meta-RL helps systems adapt to user behavior more quickly. Instead of relearning preferences from scratch every session, the model applies strategies learned across user types and behavioral shifts.

If you’re constantly A/B testing, you know the cost of slow convergence. Meta-RL helps optimize the decision-making process within experimentation — say, choosing which variant to show or when to stop a test early — by using patterns seen in previous experiments.
Yes, robotics falls under the ML umbrella, but the crossover to data science is clearer than it seems. Automation in warehouses, delivery systems, and industrial workflows relies on adapting to real-world variables. Meta-RL helps these systems respond intelligently without lengthy retraining.
Meta-reinforcement learning isn’t just another trendy machine learning buzzword. It’s a genuinely useful way to make your models more adaptive, more efficient, and quicker to respond to change — all without going back to square one every time something shifts. For data scientists, this means less time patching models and more time making progress. It’s not about creating agents that solve one problem — it’s about building systems that can face ten new ones and still land on their feet.
Advertisement
Curious about Meta-RL? Learn how meta-reinforcement learning helps data science systems adapt faster, use fewer samples, and evolve smarter—without retraining from scratch every time
Curious how stacking boosts model performance? Learn how diverse algorithms work together in layered combinations to improve accuracy—and why stacking goes beyond typical ensemble methods

Confused about MLOps? Learn how MLflow makes machine learning deployment, versioning, and collaboration easier with real-world workflows for tracking, packaging, and serving models

How the Annotated Diffusion Model transforms the image generation process with transparency and precision. Learn how this AI technique reveals each step of creation in clear, annotated detail

How Margaret Mitchell, one of the most respected machine learning experts, is transforming the field with her commitment to ethical AI and human-centered innovation

New to YARN? Learn how YARN manages resources in Hadoop clusters, improves performance, and keeps big data jobs running smoothly—even on a local setup. Ideal for beginners and data engineers

Explore how Google Cloud Platform (GCP) powers scalable, efficient, and secure applications in 2025. Learn why developers choose GCP for data analytics, app development, and cloud infrastructure

Should credit risk models focus on pure accuracy or human clarity? Explore why Explainable AI is vital in financial decisions, balancing trust, regulation, and performance in credit modeling

Learn how Apache Oozie coordinates Hadoop jobs with XML workflows, time-based triggers, and clean orchestration. Ideal for production-ready data pipelines and complex ETL chains

How Hugging Face for Education makes AI accessible through user-friendly machine learning models, helping students and teachers explore natural language processing in AI education
Learn what a Common Table Expression (CTE) is, why it improves SQL query readability and reusability, and how to use it effectively—including recursive CTEs for hierarchical data

How does HDFS handle terabytes of data without breaking a sweat? Learn how this powerful distributed file system stores, retrieves, and safeguards your data across multiple machines