Advertisement
CLIP, or Contrastive Language–Image Pretraining, has reshaped how machines connect images and language. Trained on massive image–text pairs from the internet, it handles a wide range of natural language queries. But when used with satellite images—data that looks nothing like the everyday photos CLIP was trained on—its performance drops.
These images follow a different structure, and their descriptions often use technical terms. Fine-tuning CLIP using satellite images and their captions aligns the model with this domain, making it more accurate for tasks such as land classification, disaster monitoring, and environmental mapping, where precision is crucial.
CLIP works well on general web images but falls short with satellite data. The visual structure in satellite images is different—less colour, fewer familiar shapes, and sometimes non-visible spectrum data. Trees, cities, or rivers captured from space don't resemble their ground-level counterparts. This creates confusion for CLIP's pre-trained visual encoder.
Language adds another layer of challenge. Captions for remote sensing images often contain scientific or technical terms, such as "urban heat island" or "crop stress zones," which weren't part of CLIP's original training. These terms don't match the natural, social-media-style language CLIP expects. So, it may misinterpret the image or fail to link it accurately with its caption.
That mismatch between visual features and language results in poor performance on common geospatial tasks. For instance, CLIP might struggle to tell apart wetlands and shallow water or misclassify irrigated farmland. These errors limit its usefulness in satellite-based applications.
By fine-tuning with domain-specific examples, CLIP adapts better to satellite imagery, helping it learn what features and terms matter in this context.
Fine-tuning CLIP starts with building a dataset of satellite images paired with accurate captions or labels. These images are drawn from public sources like Sentinel-2 or commercial archives. Captions describe features such as vegetation type, cloud coverage, flooding, or land use. Unlike general image labels, these require interpreting less obvious patterns in texture and tone.
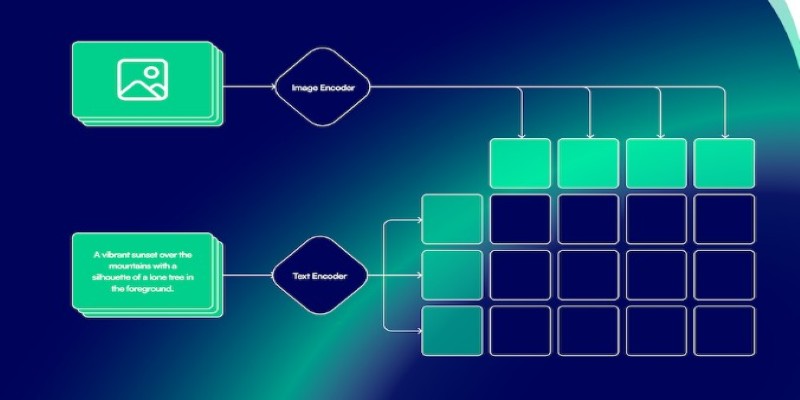
Training maintains the original contrastive learning setup—bringing matching image–caption pairs closer in embedding space while pushing unrelated pairs apart. Since CLIP already has a broad understanding of images and text, only parts of the model are fine-tuned. Often, the early layers stay frozen, and only the final layers or projection heads are updated to keep the process efficient.
Some teams use adapter layers or lightweight updates to reduce training time and avoid overfitting. This makes it easier to fine-tune even with limited computing power.
Captions for fine-tuning often come from structured sources, such as maps, reports, and classification datasets. These descriptions are more technical and aligned with specific observation tasks. For example, instead of saying "a forest in winter," a caption might say "low NDVI coniferous forest with sparse canopy."
The quality and clarity of these captions directly affect the model’s ability to learn. If they're vague or inconsistent, CLIP can’t build strong associations between visual and textual inputs. But when the language matches real-world use cases, the fine-tuned model performs much more reliably.
Once fine-tuned, CLIP becomes more effective for tasks involving remote sensing. A common use case is image retrieval. Users can input a phrase like "coastal erosion on sandy beach" or "urban development near farmland," and the model pulls up matching satellite images. This makes searching large image databases much faster and more intuitive.
Zero-shot classification is another area where fine-tuned CLIP helps. Given a set of class names—such as "industrial zone," "wetland," or "drought-stricken area"—the model can label images it has never seen before. This is especially valuable in regions with little labelled data or during emergencies when new areas need analysis quickly.
CLIP also improves visual grounding. It can find areas in an image that match a text description, like "flooded fields along riverbank." The stronger alignment between image and text means better accuracy when pinpointing key features.
Change detection and seasonal analysis benefit as well. A fine-tuned model is more sensitive to subtle differences that suggest shifts in land use, water levels, or vegetation health. It helps analysts track long-term environmental trends or respond to short-term events.
Another practical outcome is automated map creation. CLIP can help generate thematic maps where labels or layers reflect text-based queries or report content. This bridges the gap between raw satellite data and usable geographic insights.
Despite the benefits, fine-tuning CLIP for remote sensing comes with challenges. One of the biggest is the availability of clean, well-labeled data. Satellite imagery often lacks captions or uses inconsistent terminology. Creating quality datasets takes time and often requires expert input.
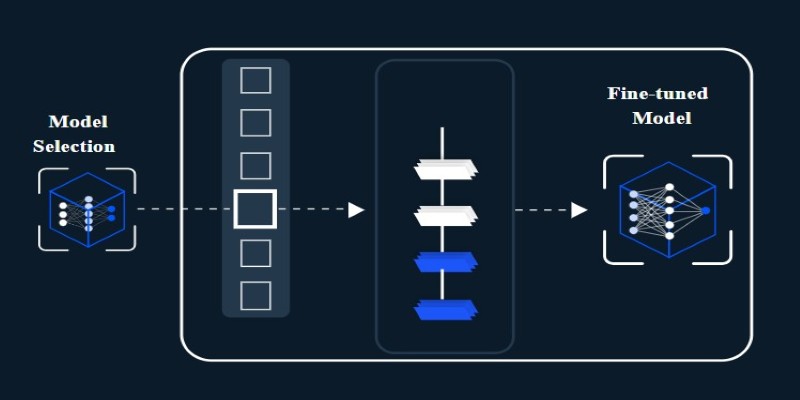
Another issue is the input format. CLIP expects RGB images, but remote sensing data often uses infrared or radar bands. These don’t translate directly into the RGB space. Some teams use false-colour composites or select bands that simulate RGB, but this can lose information.
Computational cost matters, too. Satellite images are large, and fine-tuning a big model on high-resolution data demands significant resources. Freezing early layers and using lower resolutions help, but they may limit how much the model can learn.
Generalization across regions is another hurdle. A model trained on North American landscapes may not perform well in Africa or Asia. Vegetation patterns, urban layouts, and annotation styles vary widely. Ensuring diversity in training data helps, but it doesn’t fully solve the problem.
Finally, caption quality is essential. If captions are too short, the model misses important details. If they’re too long, the main information can get lost. Fine-tuning works best when captions are concise, consistent, and tied closely to the image content.
Fine-tuning CLIP with remote sensing images and domain-specific captions makes it better suited for satellite-based tasks. It helps the model understand the unique visuals and language of Earth observation data. While the general version struggles with this kind of imagery, fine-tuning enhances performance in areas such as classification, retrieval, and mapping. Though not without challenges, this method offers a useful way to connect satellite imagery with meaningful textual insights.
Advertisement

Is your team using AI tools you don’t know about? Shadow AI is growing inside companies fast—learn how to manage it without stifling innovation or exposing your data

Confused about the difference between a data lake and a data warehouse? Discover how they compare, where each shines, and how to choose the right one for your team

How do we keep digital research accessible and citable over time? Learn how assigning DOIs to datasets and models supports transparency, reproducibility, and proper credit in modern research

How to convert transformers to ONNX with Hugging Face Optimum to speed up inference, reduce memory usage, and make your models easier to deploy across platforms

Explore how Google Cloud Platform (GCP) powers scalable, efficient, and secure applications in 2025. Learn why developers choose GCP for data analytics, app development, and cloud infrastructure
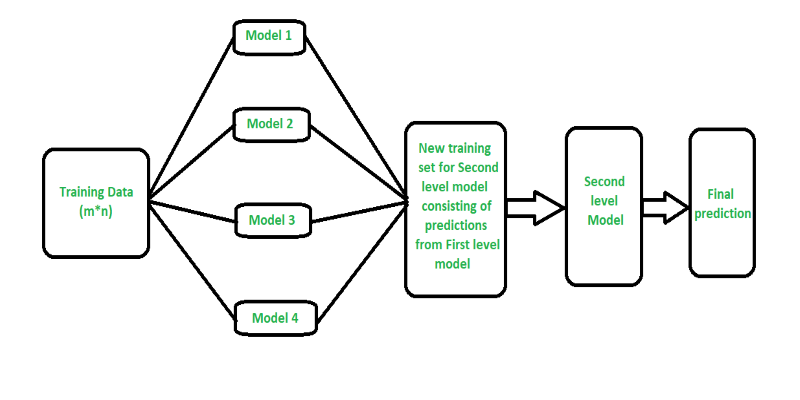
Curious how stacking boosts model performance? Learn how diverse algorithms work together in layered combinations to improve accuracy—and why stacking goes beyond typical ensemble methods

Explore how data quality impacts machine learning outcomes. Learn to assess accuracy, consistency, completeness, and timeliness—and why clean data leads to better, more stable models

Learn the full process of deploying ViT on Vertex AI for scalable and efficient image classification. Discover how to prepare, containerize, and serve Vision Transformer models in production

How fine-tuning CLIP with satellite data improves its performance in interpreting remote sensing images and captions for tasks like land use mapping and disaster monitoring

Confused about MLOps? Learn how MLflow makes machine learning deployment, versioning, and collaboration easier with real-world workflows for tracking, packaging, and serving models

A detailed look at training CodeParrot from scratch, including dataset selection, model architecture, and its role as a Python-focused code generation model

How Margaret Mitchell, one of the most respected machine learning experts, is transforming the field with her commitment to ethical AI and human-centered innovation