Advertisement
Teaching machines to write code isn’t science fiction anymore—it’s something developers and researchers are actively doing. CodeParrot is a great example of this progress. It’s a language model designed to generate Python code, trained from the ground up with no shortcuts or preloaded intelligence. Every part of its performance stems from the dataset, architecture, and training process.
Building a model from scratch means starting with nothing but data and computation, which creates both room for customization and a steep learning curve. This article walks through how CodeParrot was trained, what makes it different, and how it's being used.
CodeParrot’s dataset came from GitHub, filtered to include only Python code with permissive licenses. The team removed non-code files, auto-generated content, and other noise to ensure that what remained was usable and relevant. That decision helped the model learn useful patterns rather than clutter.

The final dataset was about 60GB. While modest in scale, the quality was high. It included practical scripts, library usage, and production-level functions—code that real developers write and maintain. This matters because the model becomes more reliable when trained on code that solves actual problems.
An important step was deduplication. GitHub has many clones, forks, and repetitive snippets. Repeated data leads to overfitting, which means the model starts echoing rather than understanding. By filtering out duplicate files, the team ensured the model had broader exposure to different styles and structures. This helps the model generate original code rather than regurgitating old examples.
CodeParrot uses a variant of the GPT-2 architecture. GPT-2 struck a balance between size and efficiency, especially for a domain-specific task like code generation. While larger models exist, GPT-2’s transformer backbone was enough to learn Python’s structure and syntax effectively.
Tokenization is how raw code is split into digestible parts for the model. CodeParrot uses byte-level BPE (Byte-Pair Encoding), which breaks input into subword units. Unlike word-level tokenizers that struggle with programming syntax, byte-level tokenization handles everything from variable names to punctuation without issue.
This approach made a difference. Programming languages rely on strict formatting and symbols. A poor tokenizer would misinterpret or overlook these. Byte-level tokenization avoided that by treating all characters as important, giving the model a consistent input format.
It also meant the model could work with unknown terms or newly coined variable names without breaking down. That flexibility is important in programming, where naming is often custom and unpredictable.
Training from scratch starts with random weights. In the beginning, the model has zero understanding—not of syntax, structure, or even individual characters. It gradually learns by predicting the next token in a sequence and adjusting when it's wrong. Over time, the model gets better at these predictions, forming an internal map of what good Python code looks like.
This process used Hugging Face's Transformers and Accelerate libraries, with training run on GPUs. The training involved standard techniques: learning rate warm-up, gradient clipping, and regular checkpointing. If any step fails, the training could stall or produce unreliable output.
As training progressed, the model started recognizing patterns like how functions begin, how indentation signals block scope, or how loops and conditionals work. It didn't memorize code but learned the general rules that make code logical and executable.
Throughout the process, the team evaluated the model’s progress using tasks like function generation and completion. These checks helped detect if the model was improving or just memorizing. They also showed whether the model could generalize—writing functions it hadn’t seen before using the rules it learned.
This generalization is what separates useful models from those that just echo their data. CodeParrot could complete code blocks or write simple utility functions with inputs alone, which showed it had internalized more than just syntax.
Once trained, CodeParrot became useful in several areas. Developers used it to autocomplete code, generate templates, and suggest implementations. It helped cut down time on repetitive tasks, like writing boilerplate or filling out parameterized functions. Beginners found it helpful as a learning aid, offering examples of how to structure common tasks.
That said, it has limits. The model doesn’t run or test code, so it can’t verify if what it produces actually works. It may write logically valid code that fails when executed. It also can’t judge efficiency or best practices. It predicts based on patterns, not outcomes. This means any generated code still needs a human touch.
Another concern is stylistic bias. If the training data leaned heavily on a particular framework or coding convention, the model might favour those patterns even in unrelated contexts. It might consistently write in a certain style or structure that doesn't fit every project. That's why careful dataset curation is important—not just for function but for diversity.
Looking ahead, CodeParrot could be extended to other programming languages or trained with execution data to better understand what code does, not just how it looks. That would open the door to models that don’t just write code but help debug and test it, too.
The idea isn’t to replace developers. It’s to reduce friction and free up time for more thoughtful work. When models like this are paired with the right tooling, they become collaborators, not competitors.
Training CodeParrot from scratch was a clean start—no shortcuts, no reused weights. Just a focused effort to build a language model that understands Python code. The process was deliberate, from building a clean dataset to fine-tuning the model's understanding of syntax, structure, and logic. What came out of that work is a tool that helps programmers, not by being perfect, but by being helpful. It doesn't aim to replace human judgment or experience. Instead, it lightens the load on routine tasks and helps people think through problems with a fresh set of suggestions. That's a useful step forward in coding and machine learning.
Advertisement

Curious why developers are switching from Solidity to Vyper? Learn how Vyper simplifies smart contract development by focusing on safety, predictability, and auditability—plus how to set it up locally

Confused about MLOps? Learn how MLflow makes machine learning deployment, versioning, and collaboration easier with real-world workflows for tracking, packaging, and serving models

Curious what’s really shaping AI and tech today? See how DataHour captures real tools, honest lessons, and practical insights from the frontlines of modern data work—fast, clear, and worth your time

Learn how to build scalable systems using Apache Airflow—from setting up environments and writing DAGs to adding alerts, monitoring pipelines, and avoiding reliability pitfalls

New to YARN? Learn how YARN manages resources in Hadoop clusters, improves performance, and keeps big data jobs running smoothly—even on a local setup. Ideal for beginners and data engineers

How Margaret Mitchell, one of the most respected machine learning experts, is transforming the field with her commitment to ethical AI and human-centered innovation
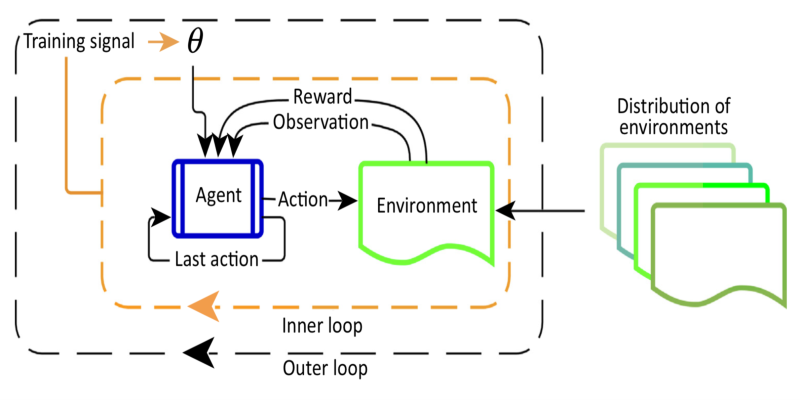
Curious about Meta-RL? Learn how meta-reinforcement learning helps data science systems adapt faster, use fewer samples, and evolve smarter—without retraining from scratch every time

How do we keep digital research accessible and citable over time? Learn how assigning DOIs to datasets and models supports transparency, reproducibility, and proper credit in modern research

Is your team using AI tools you don’t know about? Shadow AI is growing inside companies fast—learn how to manage it without stifling innovation or exposing your data

Explore how data quality impacts machine learning outcomes. Learn to assess accuracy, consistency, completeness, and timeliness—and why clean data leads to better, more stable models

A detailed look at training CodeParrot from scratch, including dataset selection, model architecture, and its role as a Python-focused code generation model

How the Annotated Diffusion Model transforms the image generation process with transparency and precision. Learn how this AI technique reveals each step of creation in clear, annotated detail